
Published 6 May 2026 | Updated 7 May 2026
Technology
PostgreSQL vs MongoDB in 2026 — The Complete Database Decision Guide
Picking the wrong database for your application is one of the most expensive mistakes you can make as a developer. It's not just about rewriting code it means migrating millions of rows (or documents), rethinking your data model, and sometimes rebuilding entire APIs from scratch. PostgreSQL vs MongoDB is the most common database debate in the backend world, and for good reason. Both are powerful, battle-tested, and widely used in production systems. But they solve different problems, and choosing between them should be based on your data, your team, and your application's real needs not trends or hype. This guide breaks down the PostgreSQL vs MongoDB decision in plain, simple terms. No jargon overload. By the end, you'll know exactly which database belongs in your stack.
PostgreSQL vs MongoDB — Quick Comparison (Featured Snippet)
| Criteria | PostgreSQL | MongoDB |
|---|---|---|
| Data model | Relational (tables, rows) | Document (JSON/BSON) |
| Schema | Rigid (ALTER TABLE required) | Flexible (schema-less) |
| ACID compliance | Full | Multi-document (since v4.0) |
| Query language | SQL (universal) | MongoDB Query Language (MQL) |
| Joins | Native, powerful | $lookup aggregation |
| AI / Vector search | pgvector extension (native) | Atlas Vector Search |
| Horizontal scaling | Citus extension / partitioning | Built-in sharding |
| Best for | Finance, ERP, analytics, AI embeddings | Real-time apps, IoT, content, mobile |
What Is PostgreSQL?
PostgreSQL (often called "Postgres") is an open-source relational database that has been around since 1986. It stores data in tables with rows and columns, and you query it with SQL — the most widely known database language in the world.What makes PostgreSQL stand out from other SQL databases is its sheer feature set. It supports JSON columns, full-text search, geospatial data, window functions, CTEs, foreign keys, and now — with the pgvector extension — native vector search for AI applications.
PostgreSQL is the backbone of financial systems, ERPs, e-commerce platforms, analytics pipelines, and increasingly, AI-powered applications. It's known for being rock-solid reliable and uncompromising on data integrity.
What Is MongoDB?
MongoDB is an open-source document database. Instead of storing data in rows and tables, it stores data as JSON-like documents (technically BSON — Binary JSON). Each document can have its own structure, fields can be nested, and you don't need to define a schema upfront.This flexibility is MongoDB's biggest selling point. If your data model changes often — which is common in fast-moving startups or IoT projects — MongoDB lets you iterate quickly without running ALTER TABLE migrations.
MongoDB's query language (MQL) is different from SQL but easy to learn. Since version 4.0, MongoDB also supports multi-document ACID transactions, which addressed one of its long-standing criticisms.
Relational vs Non-Relational Database — The Core Difference
Understanding the relational vs non-relational database distinction is the key to making the right choice.
In a relational database like PostgreSQL, your data lives in structured tables. A users table, an orders table, a products table — each linked by foreign keys. This structure enforces consistency. You can't add an order without a valid user ID. You can't delete a user who has active orders (unless you explicitly allow it). The database protects your data.
In a non-relational database like MongoDB, your data lives in documents. An "order" might be a single JSON object containing the user info, product details, shipping address, and payment status — all nested together. There's no enforced relationship between collections. This is faster to write and easier to query when you always need the full object, but it makes enforcing data integrity your application's responsibility, not the database's.
Neither approach is better. They're different tools for different problems.
When PostgreSQL Wins
Financial Systems
Finance is where PostgreSQL is unbeatable. Banking transactions, payment processing, insurance systems, and trading platforms need full ACID compliance — every transaction must either complete fully or not at all. PostgreSQL has offered this since day one, not as a bolt-on feature.
Complex joins, audit trails, referential integrity, and strict data validation are all things PostgreSQL handles natively. A double-entry ledger, for example, maps perfectly to relational tables and would be genuinely painful to implement correctly in a document store.
If money is involved, PostgreSQL is almost always the right choice.
ERP and Business Operations
Enterprise systems — HR platforms, supply chain software, CRM systems — are full of relationships. Employees belong to departments. Purchase orders have line items. Projects have tasks, and tasks have assignees. This is exactly what a relational database is designed for.
Referential integrity (foreign keys enforcing valid relationships) saves you from data corruption bugs that are nearly impossible to track down in a document store. PostgreSQL enforces these rules at the database layer, not the application layer.
Analytics and Reporting
PostgreSQL's SQL engine is genuinely powerful for analytics. Window functions, CTEs (Common Table Expressions), complex aggregations, GROUPING SETS — these are standard SQL features that let analysts and data teams write sophisticated queries without needing a separate data warehouse for many use cases.
Tools like Metabase, Grafana, Redash, and Apache Superset connect to PostgreSQL natively, making it a strong choice for internal dashboards and reporting systems.
AI Applications — pgvector Changes Everything
In 2026, PostgreSQL has become a serious player in AI infrastructure thanks to pgvector — a PostgreSQL extension that adds a native vector data type and similarity search. This turns your existing PostgreSQL database into a vector store for AI embeddings.
Instead of paying for a separate vector database (Pinecone, Weaviate), many teams now store embeddings directly in PostgreSQL alongside their application data. This simplifies the stack enormously and keeps related data in one place.
For teams already running PostgreSQL, pgvector is often the fastest path to adding RAG (Retrieval Augmented Generation) capabilities to their applications.
Geospatial Applications
The PostGIS extension gives PostgreSQL world-class geospatial capabilities — storing and querying geographic coordinates, calculating distances, finding points within polygons, and much more. It's the standard choice for mapping applications, logistics platforms, and location-based services.
When MongoDB Wins
Real-Time Applications
When your data model is changing fast — features being added, fields being renamed, new document types appearing weekly — MongoDB's flexible schema is a genuine advantage. You can push a new document structure without a migration script. You can add a field to some documents and not others.
For fast-moving product teams building real-time apps (live feeds, collaboration tools, social features), this speed of iteration matters.
Content Management Systems
Blog posts, articles, product listings, user profiles — content often has a hierarchical, nested structure. A product might have multiple images, multiple variants, multiple reviews, and multiple tags. In MongoDB, this is one document. In PostgreSQL, it's five or six tables joined together.
When you always retrieve the full document (not slices of it), MongoDB's document model is a natural fit and often faster for these access patterns.
IoT Data Ingestion
IoT is one of MongoDB's strongest use cases. Different devices send different fields. Sensor readings come in at high volume with varying schemas depending on device type, firmware version, and manufacturer. MongoDB handles this gracefully — just insert whatever arrives, index what you query, and deal with schema normalization later if you ever need to.
Trying to fit this into a rigid relational schema often requires messy EAV (Entity-Attribute-Value) patterns that are painful to query.
Mobile App Backends
Mobile apps tend to work with self-contained objects — a user profile, a notification, a message thread. These map naturally to MongoDB documents. The document you store is often very close to the JSON payload your mobile app sends and receives, which simplifies your backend code considerably.
Prototyping and MVPs
When you're building a prototype and don't yet know what your final data model looks like, MongoDB lets you move fast without committing to a schema. You can iterate on the shape of your data in days instead of weeks.
The important caveat: many teams build their MVP in MongoDB and then migrate to PostgreSQL as the data model stabilizes. MongoDB is great for starting fast; PostgreSQL is great for staying reliable.
MongoDB vs PostgreSQL Performance — What the Numbers Actually Mean
The PostgreSQL vs MongoDB speed comparison is one of the most searched topics in the database world, and the honest answer is: it depends entirely on your access pattern.
| Workload | Winner | Why |
|---|---|---|
| Simple document fetch by ID | MongoDB | Document model = no joins needed |
| Complex multi-table queries | PostgreSQL | Powerful SQL planner, native joins |
| Write-heavy, high volume | MongoDB | Flexible schema, built-in sharding |
| Aggregations & analytics | PostgreSQL | Window functions, CTE, mature planner |
| Schema-free ingestion | MongoDB | No migration overhead |
| Concurrent reads (OLTP) | Tie | Both handle this well at scale |
| Vector similarity search | PostgreSQL | pgvector with HNSW indexing |
Raw benchmarks are often misleading because they test one specific access pattern in isolation. A blog post claiming "MongoDB is 3x faster than PostgreSQL" is usually comparing MongoDB's strength (document fetch) against PostgreSQL's weakness (un-indexed join). The reverse test would show the opposite result.
The right question isn't "which is faster?" — it's "which is faster for the queries my application actually runs?"
SQL vs NoSQL Advantages and Disadvantages
Understanding SQL vs NoSQL advantages and disadvantages helps you make an informed, context-specific decision.
| Factor | SQL (PostgreSQL) | NoSQL (MongoDB) |
|---|---|---|
| Schema flexibility | Low — changes require migrations | High — any document shape accepted |
| Data integrity | Enforced at DB level | Enforced at application level |
| Query power | Very high — full SQL | Good, but complex queries are verbose |
| Learning curve | SQL is universally known | MQL is easy but less portable |
| Scaling | Vertical + partitioning/Citus | Horizontal sharding built-in |
| Transactions | Full ACID (any number of tables) | ACID (multi-document since v4.0) |
| Ecosystem | Massive — 50+ years of tooling | Growing fast, strong in JS/Node |
| Best scaling pattern | Scale-up first, then partition | Scale-out from the start |
The pgvector Revolution — PostgreSQL for AI in 2026
One of the biggest database stories of the past two years is how PostgreSQL quietly became a major player in AI infrastructure.
pgvector is a PostgreSQL extension that adds:
- A native vector data type
- Cosine similarity, dot product, and Euclidean distance operators
- Two index types: HNSW (fast queries, more memory) and IVFFlat (less memory, slightly slower)
This means you can store your AI embeddings — the numerical representations of text used in RAG pipelines and semantic search — directly in the same database as your application data.
Using pgvector for a RAG Pipeline
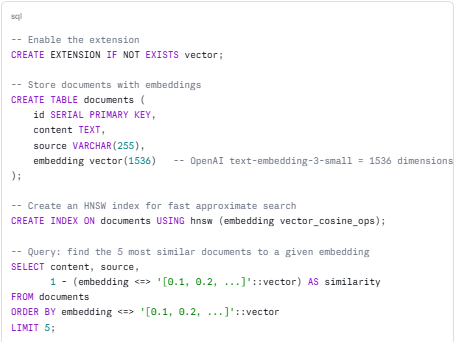
HNSW vs IVFFlat Index
| Index | Query Speed | Memory Usage | Best For |
|---|---|---|---|
| HNSW | Very fast | Higher | Production, real-time queries |
| IVFFlat | Moderate | Lower | Large datasets, memory-limited |
When pgvector Is Enough vs When You Need Pinecone/Weaviate
pgvector is enough when:
- Your vector dataset is under 5–10 million embeddings
- You're already running PostgreSQL
- You want to query vectors alongside relational data (e.g., filter by user, date, category)
- You want to minimize infrastructure complexity
Consider Pinecone or Weaviate when:
- You have 50M+ vectors and need sub-millisecond latency at scale
- Vector search is your primary workload (not a secondary feature)
- You need multi-tenant vector isolation across thousands of namespaces
For most applications in 2026, pgvector is the right starting point. Migrate to a dedicated vector DB only when you've hit concrete pgvector limitations — not preemptively.
Best Database for Web Applications — A Practical Decision Framework
The best database for web applications isn't a single answer. Here's a framework to decide:
Choose PostgreSQL if:
- Your data has clear, stable relationships (users → orders → products)
- You need strong consistency and can't afford data corruption
- You're building anything involving money, compliance, or audit logs
- You want one database for both your app data and AI embeddings
- Your team knows SQL (most developers do)
Choose MongoDB if:
- Your schema changes frequently and you need fast iteration
- You're building a content-heavy app where documents are self-contained
- You're ingesting high-volume, variable-structure data (IoT, events, logs)
- Your team is primarily JavaScript/Node.js focused (MongoDB's ecosystem shines here)
- You're building an MVP and need to move fast
Use both if:
- You have genuinely distinct workloads — e.g., PostgreSQL for transactions and billing, MongoDB for a content feed or activity log
Running two databases in one system adds operational complexity. Make sure the benefit is real before going that route.
Migrating Between Databases
PostgreSQL → MongoDB
This migration is less common but happens when teams realize they built a document-heavy system on a relational model and are fighting the schema constantly.The main work is document transformation taking normalized rows across multiple tables and denormalizing them into self-contained documents. Tools like Mongoose (Node.js ODM) help define the new document schema. The data migration itself is usually scripted in Python or Node.js.
MongoDB → PostgreSQL
This is far more common. Teams build their MVP in MongoDB, move fast, and then hit the wall: reporting is painful, joins are expensive $lookup pipelines, data inconsistency bugs are appearing, and the finance team wants proper auditing.The hard part of this migration is schema design. You have to look at your document structure, decide how to normalize it into tables, define foreign keys, and write migration scripts that transform documents into rows.
The process is:
- Map document fields to table columns
- Extract nested arrays into child tables with foreign keys
- Write and validate migration scripts on a copy of production data
- Run parallel writes to both databases during cutover
- Validate, then switch reads to PostgreSQL
- Decommission MongoDB after a safe observation window
Why Most Migrations Go Toward PostgreSQL
Data tends to mature over time. What starts as flexible, fast-moving document data eventually becomes stable enough to benefit from structure, referential integrity, and SQL's analytical power. This is why the PostgreSQL → MongoDB direction is rare and the MongoDB → PostgreSQL direction is well-documented and common.
This doesn't mean MongoDB is wrong for the early stages — it's often exactly right. It just means the direction of database maturity tends to favor relational systems for long-lived applications.
Frequently Asked Questions
Quick answers related to this article from PerfectionGeeks.
1. Can PostgreSQL replace MongoDB?
2. Is MongoDB faster than PostgreSQL?
3. When should I use both PostgreSQL and MongoDB in the same application?
Conclusion
The PostgreSQL vs MongoDB debate doesn't have one universal winner and anyone who tells you otherwise is oversimplifying.PostgreSQL is the safer long-term bet for most applications. It offers full ACID compliance, powerful SQL, mature tooling, and with pgvector a compelling story for AI workloads too. If you're building anything involving money, relationships between data, analytics, or compliance, PostgreSQL is almost certainly the right choice. MongoDB shines when your data is document-heavy, your schema is rapidly evolving, or you're ingesting high-volume data with variable structure. For MVPs, IoT platforms, content systems, and mobile backends, it's a genuinely excellent database. The practical advice for most teams in 2026: start with PostgreSQL. It can handle your relational data, your JSON documents, your analytics queries, and your AI embeddings all in one system. Switch to MongoDB (or add it) only when you have a specific, proven need that PostgreSQL genuinely can't serve.
Choose based on your data model, your team's strengths, and your application's real access patterns. The best database is the one that fits your problem — not the one that's trending on social media.

Written By Shrey Bhardwaj
Director & Founder
Shrey Bhardwaj is the Director & Founder of PerfectionGeeks Technologies, bringing extensive experience in software development and digital innovation. His expertise spans mobile app development, custom software solutions, UI/UX design, and emerging technologies such as Artificial Intelligence and Blockchain. Known for delivering scalable, secure, and high-performance digital products, Shrey helps startups and enterprises achieve sustainable growth. His strategic leadership and client-centric approach empower businesses to streamline operations, enhance user experience, and maximize long-term ROI through technology-driven solutions.
(1).jpg)
.jpg)
![MVP App Development Cost in 2026: Build Fast, Validate, Then Scale [Complete Cost Breakdown Guide]](https://perfectiongeekscloud.s3.us-east-1.amazonaws.com/uploads/1777976980033-mvp.webp)