
Published 11 May 2026 | Updated 18 May 2026
Technology
Redis in Production: Caching Patterns, Pitfalls & Scaling Guide 2026
Speed is the product. In a world where every millisecond of latency costs conversions, Redis has become the backbone of high-performance applications — from startup MVPs processing thousands of requests per second to enterprise systems handling millions. But deploying Redis without a proper strategy is like building a highway with no traffic rules. This guide unpacks every critical Redis caching pattern, common production pitfall, and scaling strategy you need to know in 2026.
What Is Redis and Why Does It Matter in 2026?
Redis (Remote Dictionary Server) is an open-source, in-memory data structure store used as a database, cache, message broker, and streaming engine. Its ability to serve data at sub-millisecond latency makes it indispensable for modern backend architectures.
In 2026, Redis caching patterns 2026 have evolved significantly. With more teams adopting microservices, edge computing, and AI-powered APIs, Redis is no longer just a simple key-value store it's a strategic layer in your entire data pipeline. Redis 8.x now ships with improved persistence options, smarter eviction policies, and native vector support for AI workloads.
Quick Fact: According to Stack Overflow's 2025 Developer Survey, Redis is the most used database among professional developers for caching workloads — for the fifth consecutive year.
Redis Caching Patterns: The Core Playbook
Understanding redis caching patterns is the single most important thing you can do before deploying Redis in production. The right pattern depends on your read/write ratio, data freshness needs, and failure tolerance. Here are the six essential patterns every engineer should know:
1. Cache-Aside (Lazy Loading) The app checks the cache first. On a miss, it reads from the database and populates the cache. This is the most commonly used pattern in production systems. It works well for read-heavy workloads where some staleness is acceptable.
2. Write-Through Every write goes to both the cache and the database simultaneously. This keeps the cache always fresh but adds a small amount of write latency. It's the go-to choice when data consistency is non-negotiable.
3. Write-Behind (Write-Back) Writes land in the cache first, then asynchronously sync to the database. This delivers ultra-fast write speeds but comes with an eventual consistency risk. If Redis crashes before flushing, you lose those writes.
4. Read-Through The cache layer automatically populates itself from the database on a miss. This keeps your application logic clean since the cache handles its own loading logic — the app just talks to the cache.
5. Refresh-Ahead The cache proactively refreshes data before the TTL expires, based on predicted access patterns. This reduces cold-start misses for high-traffic, predictable data like homepage content or popular product listings.
6. Distributed Caching Redis Cluster spreads data across multiple shards. This is essential for Redis for Microservices architectures where a single node can no longer handle the data volume or throughput required.
Redis Caching Patterns Evaluation: Which One Should You Pick?
Choosing the wrong pattern can silently destroy your application's reliability. This table covers redis caching patterns evaluation across all critical dimensions so you can make the right call for your use case.
| Pattern | Read Speed | Write Speed | Data Consistency | Best For | Complexity |
|---|---|---|---|---|---|
| Cache-Aside | Fast | Moderate | Eventual | Read-heavy apps, general use | Low |
| Write-Through | Fast | Moderate | Strong | Financial, inventory systems | Medium |
| Write-Behind | Fast | Very Fast | Weak | High-throughput logging, analytics | High |
| Read-Through | Fast | Moderate | Eventual | Simplified app logic | Medium |
| Refresh-Ahead | Very Fast | Moderate | Eventual | Predictable, high-traffic data | High |
| Distributed Cache | Fast | Fast | Eventual | Microservices, horizontal scale | Very High |
Redis Caching Patterns Implementation: Real-World Code
Knowing patterns on paper is half the battle. Let's look at redis caching patterns implementation with practical examples you can use today.
Cache-Aside in Node.js:
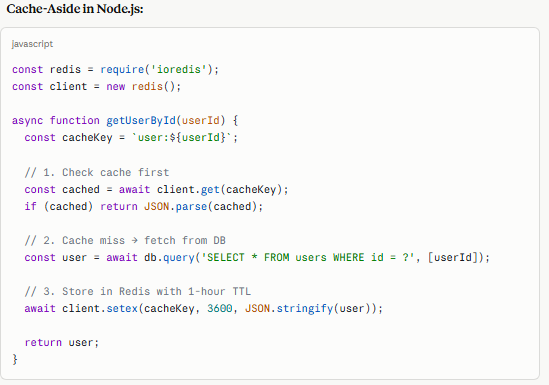
javascript
const redis = require('ioredis'); const client = new redis(); async function getUserById(userId) { const cacheKey = `user:${userId}`; // 1. Check cache first const cached = await client.get(cacheKey); if (cached) return JSON.parse(cached); // 2. Cache miss → fetch from DB const user = await db.query('SELECT * FROM users WHERE id = ?', [userId]); // 3. Store in Redis with 1-hour TTL await client.setex(cacheKey, 3600, JSON.stringify(user)); return user; }
Write-Through Pattern:
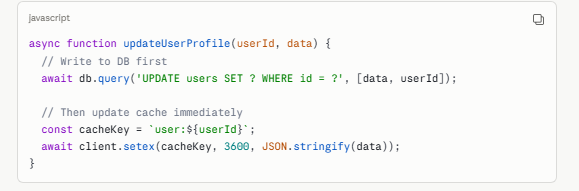
javascript
async function updateUserProfile(userId, data) { // Write to DB first await db.query('UPDATE users SET ? WHERE id = ?', [data, userId]); // Then update cache immediately const cacheKey = `user:${userId}`; await client.setex(cacheKey, 3600, JSON.stringify(data)); }
Pro Tip: Always set a TTL. Never let cache keys live forever in production — unbounded cache growth is one of the most common causes of Redis memory issues.
Redis Cache Invalidation: The Hardest Problem in Caching
There's a famous quote in computer science: "There are only two hard things — naming things and cache invalidation." Redis Cache Invalidation is where most production bugs hide. When your underlying data changes, stale cache entries can serve users wrong information for hours.
Three Invalidation Strategies:
| Strategy | How It Works | Risk Level | Recommended Use |
|---|---|---|---|
| TTL-Based Expiry | Keys auto-expire after a set time period | Low | General purpose, non-critical data |
| Event-Driven Invalidation | App sends a DEL command on data mutation | Medium | User profiles, product pages |
| Versioned Cache Keys | Key includes a version number; increment on update | Low | Complex nested data structures |
Watch out for Cache Stampede! This happens when a popular key expires and thousands of requests simultaneously hit your database. Use the "probabilistic early expiry" technique or Redis locks (SET NX) to prevent it.
Redis Performance Optimization: Getting the Most Out of Your Setup
Raw caching is only the beginning. Real redis performance optimization involves tuning your configuration, connection handling, and data serialization.
Connection Pooling Never create a new Redis connection per request. Use connection pools like ioredis (Node.js) or redis-py's built-in pool (Python). Unchecked connections eat memory and cause timeouts under load.
Pipelining for Batch Operations Redis processes commands sequentially over the network. Pipelining batches multiple commands into a single round trip, cutting network overhead by up to 80%.
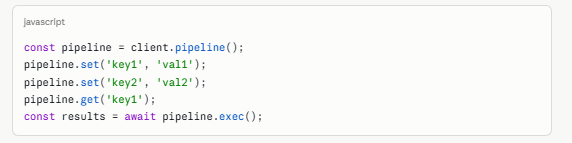
javascript
const pipeline = client.pipeline(); pipeline.set('key1', 'val1'); pipeline.set('key2', 'val2'); pipeline.get('key1'); const results = await pipeline.exec();
Choosing the Right Data Structure:
| Use Case | Best Redis Data Type | Why |
|---|---|---|
| User sessions | HASH | Field-level access without full deserialization |
| Leaderboards / rankings | SORTED SET (ZSET) | O(log N) score-based ordering |
| Rate limiting | STRING + INCR | Atomic counter increments |
| Pub/Sub messaging | PUBLISH / SUBSCRIBE | Native message delivery between services |
| Unique visitor counts | HyperLogLog | Probabilistic counting at <1% error, tiny memory |
| Geolocation features | GEO | Native geo-radius queries |
Redis Memory Optimization: Don't Let Redis Eat Your RAM
Redis Memory Optimization is critical because Redis stores everything in RAM. Poor memory hygiene leads to evictions, crashes, and degraded performance.
1. Set a maxmemory Policy Always configure a maxmemory limit and choose an eviction policy. The most common for caches is allkeys-lru — evict the least recently used key when memory is full.

# redis.conf maxmemory 4gb maxmemory-policy allkeys-lru
2. Use Hash Encoding for Small Objects For small hashes (under 128 fields with values under 64 bytes), Redis automatically uses a compact "ziplist" encoding that uses up to 10× less memory than a regular hash table.
3. Compress Large Values For JSON blobs or large strings, compress before storing. Libraries like msgpack or snappy can reduce value sizes by 50–70%, meaning your same RAM holds far more cached objects.
Pro Tip: Run redis-cli --bigkeys regularly in production to identify memory hogs before they become incidents.
Redis for Microservices: Shared Cache vs. Dedicated Cache
When using Redis for Microservices, the most important architecture decision is whether each service gets its own Redis instance or shares a central cluster.
| Approach | Pros | Cons | Best For |
|---|---|---|---|
| Shared Redis Cluster | Cost-efficient, cross-service data sharing | Noisy-neighbor risk, key namespace collisions | Small teams, fewer than 10 services |
| Dedicated per Service | Full isolation, independent scaling | Higher infra cost, harder to maintain | Large orgs, compliance-heavy environments |
| Redis Cluster + Namespacing | Middle ground — logical isolation on one cluster | Requires strict key naming conventions | Most production microservice setups |
Always prefix your keys with the service name to avoid collisions: orders:user:123 instead of just user:123. This small habit prevents midnight incidents when two teams accidentally share a key name.
Common Production Pitfalls and How to Avoid Them
Even experienced teams make these mistakes when running Redis in Production:
- No persistence configured: By default Redis is in-memory only. Enable RDB snapshots or AOF persistence for disaster recovery.
- Using KEYS * in production: This command blocks the server and scans every key. Use SCAN instead — it's non-blocking and cursor-based.
- Storing everything as JSON strings: Deserializing large JSON blobs on every request kills performance. Use Hashes for structured data.
- No monitoring: Deploy Redis without Prometheus or Datadog metrics and you're flying blind. Track used_memory, cache_hit_ratio, and connected_clients.
- Single-point-of-failure: A single Redis node without replication means a crash takes your app down. Always run Redis Sentinel or a Cluster setup in production.
- Unbounded key growth: Forgetting TTLs means your cache grows until Redis hits maxmemory and starts evicting keys unpredictably.
Scaling Redis in 2026: From Single Node to Cluster
Scaling Redis follows a clear progression. Start simple and add complexity only when you need it:
- Phase 1 — Single Node: Works for most startups. Add read replicas when reads become the bottleneck.
- Phase 2 — Redis Sentinel: Automatic failover for high availability without horizontal sharding. Good up to ~50GB of data.
- Phase 3 — Redis Cluster: Automatic horizontal sharding across 3–1000 nodes. Built-in replication. Handles petabyte-scale workloads.
2026 Tip: Redis Cloud (Upstash, AWS ElastiCache, Redis Enterprise Cloud) now offers serverless Redis with true pay-per-use billing — a great option for teams that want to skip infrastructure management entirely.
Frequently Asked Questions
Quick answers related to this article from PerfectionGeeks.
1. What is the best Redis caching pattern for a high-traffic e-commerce site?
2. How do I prevent cache stampedes in Redis?
3. Is Redis suitable for session storage in microservices?
4. How much memory does Redis use per key?
5. What's the difference between Redis Sentinel and Redis Cluster?
Conclusion
Redis continues to be one of the most reliable technologies for building fast, scalable, and high-performance applications. However, successful deployment depends on choosing the right Redis caching patterns 2026, implementing proper cache invalidation, optimizing memory usage, and planning infrastructure scaling carefully. From redis performance optimization to Redis for Microservices, every strategy plays a critical role in maintaining stability and speed. Businesses that invest in proper Redis architecture can improve user experience, reduce database load, and scale efficiently. For expert Redis implementation and backend scaling solutions, PerfectionGeeks provides industry-ready development expertise tailored for modern applications.

Written By Shrey Bhardwaj
Director & Founder
Shrey Bhardwaj is the Director & Founder of PerfectionGeeks Technologies, bringing extensive experience in software development and digital innovation. His expertise spans mobile app development, custom software solutions, UI/UX design, and emerging technologies such as Artificial Intelligence and Blockchain. Known for delivering scalable, secure, and high-performance digital products, Shrey helps startups and enterprises achieve sustainable growth. His strategic leadership and client-centric approach empower businesses to streamline operations, enhance user experience, and maximize long-term ROI through technology-driven solutions.


